Generative 3D Reconstruction
via Joint Object and Pose Modeling
Introducing Cupid, a 3D generator that accurately infers the
camera pose, 3D shape, and texture from a single image.
Novel Generative Formulation: We reframe 3D reconstruction by jointly
synthesizing the object and its camera pose. This grounds the generation process, creating
an explicit link between the 3D output and the 2D input view.
Pose-Conditioned Architecture: We design a generator with a pose-aligned
conditioner. This novel mechanism directly injects pixel information into the
synthesis
process to prevent color drift and ensure textural fidelity.
Unified and Versatile Model: Our approach is a unified, versatile model
that
excels at diverse 3D synthesis tasks, including single image reconstruction, scene
generation, and multi-view reconstruction, without task-specific tuning.
TL;DR: Create canonically posed 3D objects and object-centric cameras from any images in a few forward steps.
Abstract
We present Cupid, a new generation-based method for single-image 3D reconstruction. Our approach jointly infers camera pose, 3D shape, and texture by formulating the task as a conditional sampling process within a two-stage flow matching pipeline. This unified framework enables robust pose estimation and achieves state-of-the-art results in both geometric accuracy and visual fidelity.
Video
Interactive 3D Visualization
TipHow to inspect camera views
Double-click a camera frustum in the scene to jump to that camera's view. Then open the control panel (top-left) and use the Image Opacity slider to compare the camera image with the 3D model.
Scene / multi-view examples are available at the end of the thumbnail list.
How Cupid Works?
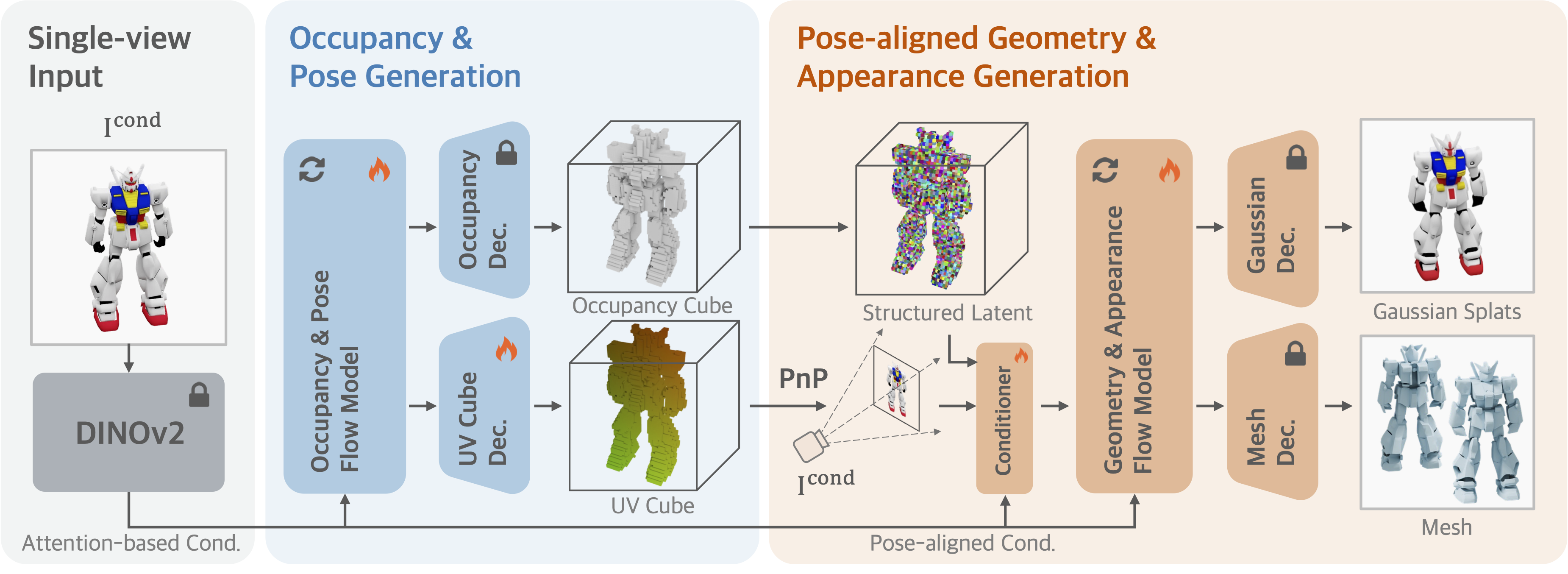
We use a powerful generative technique called Flow Model. This model learns to transform random noise into a voxelized 3D representation, guided by the input image. To make this process efficient and effective, we break it down into two main stages, as shown in Figure 1.
Figure 1: Overview of Cupid. Our two-stage process first generates a coarse shape and a novel "UV cube" to determine the camera pose. This pose then guides a second stage to generate high-fidelity geometry and appearance.
Stage 1: Occupancy and Pose Generation.
The first stage generates a coarse representation of the object and simultaneously estimates the camera pose. Given an input image, our flow model produces two key outputs: an occupancy cube (indicating which voxels $\mathbf{x}_i$ in space belong to the object) and a novel UV cube (indicating the 2D pixel locations $\mathbf{u}_i$ for each 3D voxel).
we can robustly solve for the camera's projection matrix $\mathbf{P}^{*}$ using a classical least-squares solver.
Stage 2: Pose-Aligned Geometry and Appearance Generation.
With the camera pose now known, the second stage generates the fine-grained geometry and appearance. A common problem here is "color drift" and "detail inconsistency", where the 3D model doesn't perfectly match the input image's colors and details. We solve this with a pose-aligned conditioner that inject pixel-wise information.
For each voxel in the occupancy cube, we use the calculated pose to find exactly where it lands on the 2D input image. We then sample features (both high-level semantics from DINO and low-level color/texture) from that precise pixel location. These pixel-aligned features are injected directly into the generation process, ensuring the final 3D model has high-fidelity geometry and appearance that is faithful to the input view.
Extension 1: Composing Components for Full Scene Reconstruction
Our framework naturally extends to reconstructing entire scenes. We use an object detector (like SAM) to find all objects in an image. Then, we run our reconstruction process on each object independently.
Then, using the 3D-2D correspondences our method provides, we align each reconstructed object with a global depth prior (from a model like MoGe). This allows us to solve for each object's correct scale and position, composing them into a single, coherent 3D scene.
Figure 2: Component-Aligned Scene reconstruction. By reconstructing each object and then solving for its similarity transformation, we can accurately compose complex 3D scenes.
Extension 2: Multi-view Reconstruction
Although Cupid is trained with single image condition, it can be easily extended to multi-view reconstruction, thanks to the flexibility of our generative framework.
Given multiple images of the same object from different angles, we know that the 3D object cube should be the same across all views.
Therefore, we can run our flow model for each image, but share the same occupancy latent $\mathbf{X}$ across all views during the iterative flow sampling. This is similar to MultiDiffusion (which average the overlapped pixel regions in 2D during iterative sampling), but in the 3D space.
Figure 3: Multi-view conditioning. When multiple input views are available, we fuse the shared, view-agnostic object latent across flow paths (similar to MultiDiffusion), enabling camera, geometry and texture refinement across all images. Top: inputs; Middle: reconstructed 3D object and camera poses; Bottom: rendered images and geometry.
BibTeX
@article{huang2025cupid,
title={CUPID: Generative 3D Reconstruction via Joint Object and Pose Modeling},
author={Huang, Binbin and Duan, Haobin and Zhao, Yiqun and Zhao, Zibo and Ma, Yi and Gao, Shenghua},
journal={arXiv preprint arXiv:2510.20776},
year={2025}
}
Acknowledgement
We thank NYU VisionX for the nice project page template.